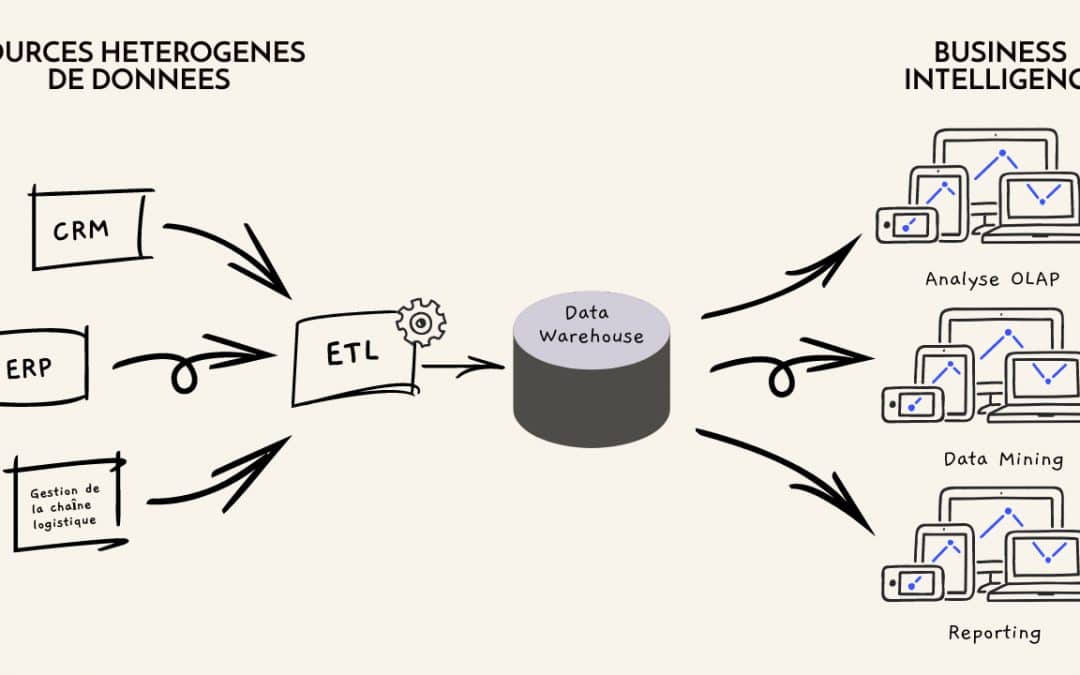
Les PME/PMI produisent et collectent, à intervalles réguliers, des données en provenance de sources disparates : plateforme cloud, CRM, site web, etc. L’exploitation de toutes ces informations cloisonnées et éparpillées dans divers services est devenue, pour ces entreprises, un réel enjeu.
Pour relever le défi de la gestion de toutes les informations collectées et en faire des ressources qualifiées exploitables par la Business Intelligence, de nombreuses entreprises se tournent vers des outils d’informatique décisionnelle.
L’un des processus les plus utilisés par les logiciels d’informatique décisionnelle est l’ETL. Qu’est-ce et quelle utilité revêt-il pour la Business Intelligence ? Cap sur le rôle, le fonctionnement et la portée d’une des technologies informatiques intergicielles les plus usitées en BI.
ETL : qu’est-ce que c’est ?
Principe de l’ETL
L’ETL, pour Extract Transformation and Load, est un processus destiné à permettre l’extraction, la transformation et le chargement de données recueillies par divers canaux. Il s’agit d’un processus automatisé qui, à partir des données brutes, extrait l’information à analyser, la formate de sorte qu’elle soit exploitable pour les besoins opérationnels et la charge, au final, dans un Data Warehouse.
Comment fonctionne l’ETL ?
Comme l’indique son nom, l’ETL est un processus en 3 phases : l’extraction, la transformation et le chargement.
L’extraction (Extract)
C’est la première des étapes. Les données y sont identifiées et sélectionnées depuis les systèmes de stockage (ERP, SGBD, etc). Ces données peuvent avoir diverses sources : applications, systèmes de base de données, feuilles de calcul, logs d’activité, événements de sécurité…
Ce ne sont pas toutes les données extraites durant cette phase qui seront nécessaires à la suite du processus. En effet, l’identification formelle du sous-ensemble exact d’intérêt se révélant difficile à cette étape, la quantité de données requises (elle peut aller de quelques centaines de kilo-octets à plusieurs giga-octets) est extrapolée de sorte à couvrir tous les besoins.
La transformation (Transform)
Cette étape est la plus importante des trois. À cette phase, les données brutes sont nettoyées et traitées de sorte à répondre au format de reporting adopté par l’entreprise. Cette transformation se fait suivant un certain nombre de pratiques. Voici les plus courantes.
- La standardisation : il y est question de la définition des données à traiter, de leur format et de leur mode de stockage ;
- La déduplication : il s’agit essentiellement d’exclure ou de supprimer au choix les doublons ;
- La vérification : cette tâche automatisée a pour objectif d’éliminer les données inutilisables et de remédier aux éventuelles anomalies qui auraient pu avoir cours jusque-là ;
- Le tri : ce processus sert à grouper et à stocker les données selon leurs catégories.
Selon les règles internes de reporting de l’entreprise, d’autres tâches peuvent s’ajouter à celles déjà énumérées.
Le chargement (Load)
C’est la dernière étape du processus de l’ETL. Cette phase est celle de l’insertion des données dans le Datamart ou le Data Warehouse. Cette insertion une fois faite, ces données peuvent être exploitées par différents outils décisionnels et ainsi servir à des reportings, des analyses géographiques ou encore des analyses multidimensionnelles OLAP.
Le chargement durant le processus d’ETL peut se faire selon 3 modes :
- Le chargement initial : les enregistrements sont remplis dans l’entrepôt de données
- La charge incrémentale : les modifications (mises à jour) sont appliquées selon les règles internes de l’entreprise
- L’actualisation complète : les nouveaux enregistrements sont chargés dans l’entrepôt et écrasent les anciens contenus.
ETL : quel en est l’intérêt pour la BI ?
De plus en plus d’outils d’informatique décisionnelle tels que Knowage, OpenText Magellan ou encore Qlik Sense font la part belle à l’ETL. Face à ce recours fréquent, une question se pose : celle de l’utilité de cette technologie informatique dans la Business Intelligence. Voici donc à quoi peut servir l’ETL dans l’informatique décisionnelle.
Une plus grande efficacité des projets d’intégration
La réussite des stratégies data repose sur l’intégration de données qualifiées et unifiées. Avec l’ETL, l’extraction et le mappage des données devient plus facile et leur traitement s’en trouve plus simplifié en raison de l’automatisation du processus et des volumes de données susceptibles d’être pris en charge.
En effet, l’ETL repose sur des scripts plus rapides que la programmation traditionnelle. Les données sont, grâce à ce processus, traitées par lots de façon automatique. L’ETL peut, par exemple, servir à transférer d’énormes volumes de données entre 2 systèmes selon un calendrier défini et accomplir dans le même temps, au quotidien, des tâches disparates sans que l’une des 2 opérations influe sur l’efficience de l’autre.
Une migration plus rapide et plus sécurisée
Le principal enjeu des migrations est de rendre les données rapidement disponibles et exploitables. Pour que cela puisse advenir, ces données doivent être qualifiées, formatées selon les règles internes à l’entreprise et triées. Appliquer des algorithmes sur des données brutes, c’est bien connu, conduit très souvent à des résultats ambigus.
L’ETL garantit des informations de qualité grâce à son processus durant lequel toutes les données sont nettoyées, structurées et formatées afin d’être facilement analysées et interprétées. Ces données sont, de plus, traitées de manière à éviter les doublons et chargées vers un référentiel unique.
Les informations ayant passé le cap de la migration sont sécurisées, directement exploitables et il n’est nul besoin de vérification, tout ayant été fait en amont de façon automatique.
Une centralisation et une vue unifiée des données
L’ETL dessert les intérêts de la stratégie Master Data Management adoptée par de plus en plus d’entreprises en lieu et place des structures cloisonnées en silo. Avec l’ETL, toutes les données recueillies sont acheminées dans un seul Data Warehouse et organisées par thématique.
Cette centralisation permet également une actualisation et une synchronisation rapides de toutes les informations tout en faisant bénéficier aux équipes d’une vue unifiée, état de choses qui améliore grandement la collaboration.
Des applications à de nombreux projets
L’ETL peut également servir à de nombreux autres projets de Business Intelligence. On y compte la synchronisation des applications, la migration de logiciels, le développement d’API ou encore celui de webservices, etc.
Vous souhaitez en savoir plus sur le processus ETL ou déployer un projet de Business Intelligence au sein de votre entreprise ? Les experts de Stere Informatique vous accompagnent dans tous vos projets. Contactez-nous.
